Transformers, QKV, & Stacking
The transformer block is a core component of the GPT (generative pretrained transformer) architecture that includes multi-head self-attention, layer normalization, a feed forward network with GELU activation, and shortcut connections. I will cover these features, the full GPT architecture, and also take a deeper dive into the relationship and impacts of Query, Key, and Value in self-attention.
Layer Normalization
Layer normalization adjusts the outputs of a neural network to have a mean of 0 and variance of 1. This keeps training consistent and avoids vanishing gradients. We can implement layer normalization using the following formula:
- xinput vector
- μmean of the input
- σ²variance of the input
- γlearnable scale parameter
- βlearnable shift parameter
- εsmall constant to avoid division by zero
The scale and shift parameters are trainable parameters tuned during backpropagation to optimize model performance. In modern architectures like GPT-2, layer normalization is typically applied before the attention or feed forward network, whereas in older models like the original transformer it is applied after those modules.
Feed Forward with GELU
Another part of the transformer block is a small feed forward neural network with a GELU activation function. Many people are familiar with the ReLU activation function, but GELU is commonly used as it is smoother and can lead to better optimization and gradient flow during training.
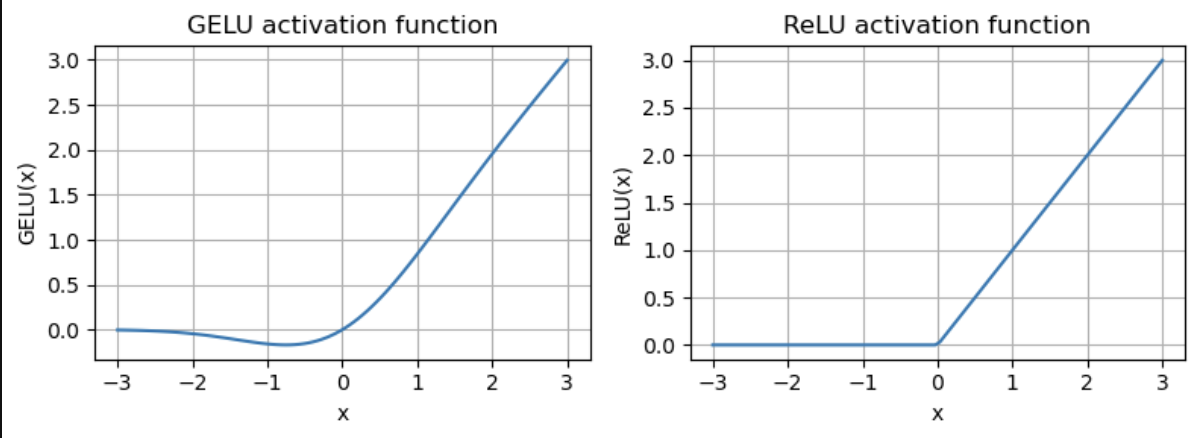
GELU vs ReLU activation functions.
The transformer block's feed forward layer increases the input dimension by a factor of 4 to project the data into a richer representation space, applies the nonlinear GELU activation, then scales the dimension back down by 4 to match the output to the input size. While the attention module captures the contextual relationships between tokens, this feedforward network processes each token independently. The nonlinearity of the GELU activation is crucial, as it allows the model to learn complex patterns like in human language.
Shortcut Connections
Shortcut connections, also known as skip or residual connections, are used to combat the vanishing gradient problem where a gradient becomes too small in a deep neural network making training difficult and inefficient. A skip connection just maps the output of a layer to the output of a later layer, shortening the path of the gradient in the backward pass.
Transformer Block
The transformer block, introduced in the paper "Attention Is All You Need", uses all of these features alongside a multi-head attention mechanism. The transformer covered in the paper was designed for machine translation and consisted of an encoder and decoder. I will cover the transformer architecture used in the GPT-2 model, which consists only of the decoder for autoregressive text generation, along with some other small architecture changes.
The transformer block used in GPT-2 starts with layer normalization and a multi-head self-attention mechanism, followed by dropout and the addition of a skip connection. Next, it applies another layer normalization and the feedforward neural network with GELU activation, followed by dropout and the addition of the skip connection from the output of the first attention sub-block.
The multi-head self-attention mechanism and feed forward network are both key parts of the architecture. Attention captures the relationship between tokens, learning the complexities of human language. The feedforward network with nonlinear GELU activation is necessary to modify and learn individual tokens.
This is the architecture used in GPT-2, but many current models have similar architecture, with the internal mechanisms optimized for scaling, inference, and increased context window sizes.
GPT Architecture
The full GPT architecture takes in and tokenizes raw text, creates token and positional embeddings, and applies dropout. This sequence is then passed through a stack of transformer blocks, followed by a final layer normalization and linear output layer projecting the output into a vector of logits the size of the vocabulary. These logits represent the raw unnormalized scores for each next possible token, and the highest probability prediction of the next token can be taken with greedy decoding by taking the index of the maximum value.
Since it is autoregressive, this predicted token is appended to the sequence and passed back into the model, repeating the process for a specified number of times or until an end-of-text token is generated.
QKV Experiment
I dove deeper into the relationship between the Query, Key, and Value matrices in the attention mechanism. To do this, I calculated the attention weights and output vectors for several different edge cases, visualizing the results below:
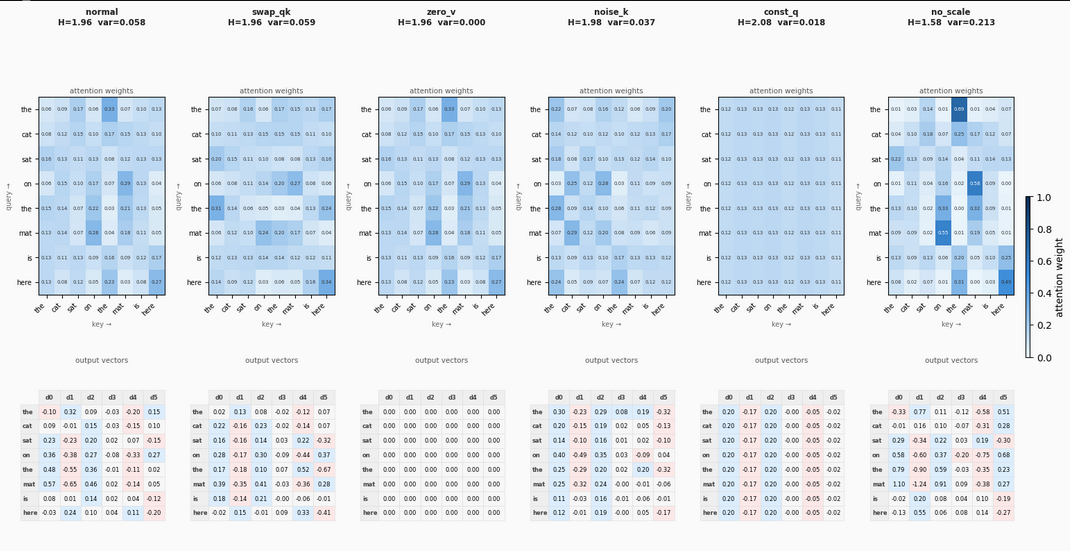
Attention weights and output vectors for various QKV configurations.
The "Normal" section visualizes the intended relationship between the three components. The Queries represent what each token is looking for, the Keys represent what context each token holds, and the Values represent the actual information used to update the token's understanding and create the final output vector.
To test how the network reacts, I modified the vectors and observed the following:
- Swapping Query and Key: The attention pattern scrambles entirely, and the resulting weights become meaningless.
- Zeroing out the Value: The output vectors all become exactly zero, cleanly demonstrating that the output is entirely dependent on the Value matrix.
- Filling the Key with Gaussian Noise: The attention weights become spread out and random, as the queries cannot find meaningful structures to attend to.
- Using a Constant Query: Every token is effectively asking the exact same question. Because the key is the only differentiator, every row in the attention map becomes identical, resulting in identical output context vectors for every token.
- Removing the Scaling Factor: Without scaling the attention scores before the softmax function, the weights take on a much wider range of extreme values. This pushes the softmax function into its flat regions, which leads to vanishing gradients in deep networks.
Conclusion
Like attention, I had already implemented this code when following Sebastian Raschka's book "Build a Large Language Model (From Scratch)", but gained a deeper understanding for transformers when re-reading the chapter on them. I challenged myself to recall the architecture and implement the code without following the book as much as I could this time.
The transformer and GPT architecture is not very complex to understand or implement compared to the attention mechanism. The most interesting part to me is understanding the reason behind each feature and how it impacts the performance of the network and model.
References
- "Build a Large Language Model (From Scratch)" by Sebastian Raschka
- https://www.youtube.com/watch?v=nZrZOI0oRuw
- https://medium.com/ai-assimilating-intelligence/understanding-query-key-value-in-transformers-c579b93054cc