Tokenization & Embeddings
Tokenization
Tokenization is the process that turns raw text into sequences of integers for LLMs to process. Although it isn't as exciting as other components of language models, it is an essential part that should not be brushed over. An LLM cannot be trained without a tokenizer, tokenization influences the cost of prompts, and can cause security and safety issues if not implemented correctly. Common LLM limitations like spelling and arithmetic errors, or poor performance on non-English languages also stem from tokenization, highlighting the importance of the topic.
Because language models cannot process text directly, we must break down the text into an input the network can understand. The first part of this process involves breaking the text up into smaller tokens and assigning them token IDs. Text can be tokenized on the character, word, or subword level. Many modern algorithms focus on the subword level, breaking down complex words while keeping common ones whole. For this project, I researched and implemented the Byte-Pair Encoding (BPE) algorithm, which is used in OpenAI's GPT models.
Before diving into BPE, I want to talk about the choice of vocabulary size. The vocabulary is the mapping between tokens and token IDs after tokenization, and the choice of size is a key feature that impacts the performance of the LLM. If you choose a larger vocabulary size, more tokens will be merged together, resulting in larger tokens. This leads to fewer tokens per input sequence, which results in faster training and inference. The downside to increasing the vocabulary size is that the embedding map in the LLM gets larger, and the last layer must map the outputs to a higher dimension, both of which can increase the required compute. Because of this trade-off, vocabulary size is an important choice. For reference, many frontier models today use vocabularies ranging from tens of thousands to hundreds of thousands of tokens.
Byte-Pair Encoding (BPE)
The BPE algorithm is fairly simple: it iteratively replaces the most common pairs of characters or tokens. This algorithm compresses the input sequence to a smaller length and increases the size of our vocabulary. Here is an example taken from the Byte-Pair Encoding Wikipedia page:
aaabdaaabac ZabdZabac (Z=aa) ZYdZYac (Y=ab, Z=aa) XdXac (X=ZY, Y=ab, Z=aa)
In this example, the data cannot be compressed any further, but in practice you can keep iterating until you reach a specified vocabulary size.
For my implementation, I followed Andrej Karpathy's YouTube video "Let's build the GPT Tokenizer" where he walks through the basics of BPE and gives you a chance to implement the algorithm yourself. I implemented a regex tokenizer which is the approach OpenAI uses. It utilizes a regex pattern to split the text by categories, tokenizes each category independently, and then concatenates the results back together. This step avoids merging specific characters together, which could result in having multiple versions of words with punctuation attached.
The implementation consists of a train, encode, and decode function. The train function takes in an input text, converts it to raw bytes using UTF-8 encoding, assigns integer IDs to these bytes, and then applies the BPE regex algorithm until the specified vocabulary size is reached. Following the video, I trained my tokenizer on the Taylor Swift Wikipedia page and experimented with different vocabulary sizes. The encode function converts text to token IDs, merging pieces of the text together if allowed by our vocabulary. Lastly, the decode function converts integers to text using our vocabulary. Below is an image from a token visualizer I built, displaying the output of the tokenizer trained for a vocabulary of size 10,000.

Token visualizer output for a vocabulary of size 10,000.
Embeddings
Once we have the token IDs, we need to give the numbers some meaning. The naive approach to this is one-hot encoding, which I will cover first, then moving to a significant improvement: learned embeddings that capture the semantic meaning of text.
One-hot encoding represents each token as an array with a length of the vocabulary size. In this array, the index of the token ID is assigned the value 1, and every other index has value 0. With this approach, it is impossible to capture the semantic similarity between tokens. For example, the similarity between "king" and "queen" would be exactly the same as the similarity between "king" and "car".
Learned embeddings transform discrete text into continuous vector spaces, and represent each token as a vector of a smaller dimension containing floating point values. Modern embeddings can range from 256 to 4096 dimensions. These values are randomly initialized and then learned through backpropagation during the neural network's training. While this initial embedding layer maps each token to a single static vector, modern LLMs like GPT-4 and DeepSeek pass these vectors through self-attention layers to create contextualized representations based on the context of the word.
We can capture semantic similarity of two token embeddings by calculating their cosine similarity. A cosine similarity of 1.0 means the two vectors are pointing in the same direction and the tokens are exactly the same. A cosine similarity of 0 means the vectors are orthogonal and the tokens are unrelated.
Cosine Similarity = cos(θ) = (A · B) / (‖A‖ ‖B‖)
To visualize the difference of these methods, I created one-hot encoding and learned embedding matrices based on a small vocabulary and plotted their cosine similarities.
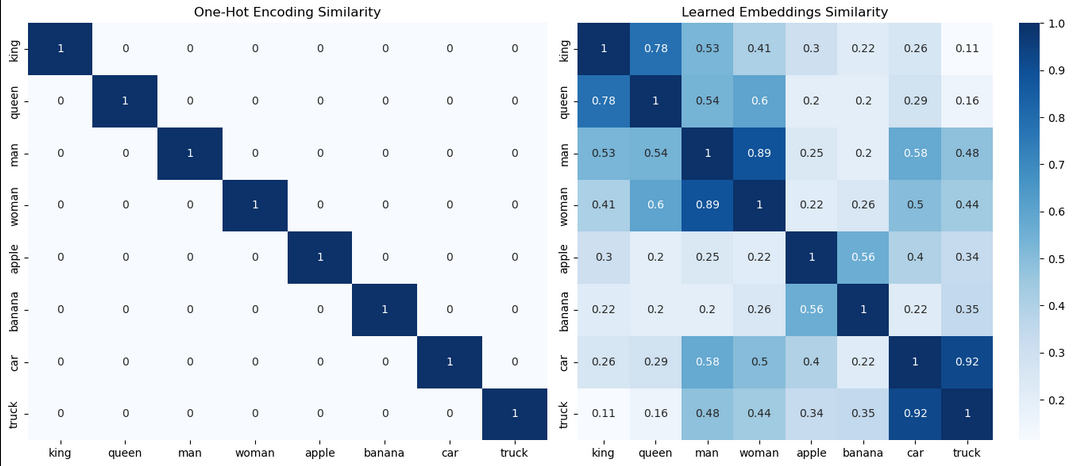
Left: one-hot encoding cosine similarities. Right: learned embedding cosine similarities.
In the one-hot encoding similarity, we can see that each token only has similarity to itself and everything is orthogonal, as expected. The learned embeddings show how similar each token is to each other. Note how it captures the differences in similarity between tokens like "king" and "queen", "king" and "man", and "king" and "banana".
Conclusion
After completing this project and write-up, I've learned how important tokenization and embeddings are to the overall performance of an LLM. Previously, I didn't realize how many different types of tokenizers exist, and that there are key design decisions that impact the LLM performance. I always thought it was just simple breaking up of text. Embeddings were especially interesting to me, how vectors can be learned to represent the meaning of a textual word. Ultimately, building these components from scratch and researching them have deepened my understanding of the process significantly.
References
- https://ahmadosman.com/blog/first-came-the-tokenizer/
- https://www.youtube.com/watch?v=zduSFxRajkE&t=1430s
- https://en.wikipedia.org/wiki/Byte-pair_encoding
- https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- https://www.freecodecamp.org/news/how-does-cosine-similarity-work/