Attention
What is Attention?
Attention is a mechanism that allows models to consider the relevancy, or 'attend to' specific parts of the input passed in to them. While attention was originally used to improve RNN based language models, in 2017 the paper "Attention Is All You Need" introduced the Transformer architecture, proving that RNNs were not necessary in language models, and the models could rely solely on attention. There are two main types of attention, self-attention which is what is used in LLMs, and cross-attention which processes two different types of inputs like different languages or modalities.
Self-Attention
Self-attention is one of the most important parts of the transformer architecture and transformer based LLMs. It is a mechanism that allows each element in the input sequence to consider the importance of every other element in the sequence.
A self-attention mechanism uses representations called the query and key to compute normalized attention weights for each token in the input, and then computes context vectors for the whole input based on these attention scores and another representation called the value. The query is a representation of a single token that asks the question "What am I looking for?". The 'answer' to a query is called the key, with the information about a token. To measure how well each key matches each query, we can compute the dot product of the two. Lastly, the value is the underlying meaning of a token that is used if the key is deemed important by a query.
In a LLM, we start with token embeddings and Query, Key, and Value weight matrices that are initialized and learned through training. Using these weight matrices and token embeddings we can create query, key, and value vectors for each token. Then, for each token we compute the dot product of the query and key to get what we call attention scores. We then normalize the attention scores using the softmax function on the attention scores divided by the square root of the embedding dimension of the keys (to avoid small gradients in training). The normalized attention scores are called attention weights. Finally, we compute a context vector for each input token, which is a weighted sum of the attention weights and value vectors for each token.
Causal Attention
In many models, we want the self-attention mechanism to consider only previous tokens to the current position in a sequence, since we only want the next word prediction to consider previous tokens. Causal attention solves this problem by adding a mask over all future tokens in a sequence, so the attention mechanism only considers previous tokens. To do this, we can create a binary mask with zero in all previous positions. An even more efficient way to do this is to replace the zeros in the mask with '-inf' values, which get turned into zero when the softmax function is applied computing the attention weights. Once the mask is created we can multiply it by our attention scores, and the rest of the attention mechanism remains the same.
Multi-Head Attention
Multi-head attention is just running multiple causal self-attention heads to allow the model to learn different relationships of the tokens in the sequence. The naive and inefficient way would be to stack causal attention modules and run each sequentially, concatenating the result of each at the end. The more efficient way to implement multi-head attention is by reshaping the query, key, and value tensors to represent multiple heads. Then compute the attention weights and then reshape the context vectors to combine the heads at the end. Although more mathematically complex, this is a key improvement as it allows the attention heads to run in parallel. For reference of size in practice, the smallest GPT-2 model has 12 attention heads per transformer block, and the largest GPT-2 model has 25 attention heads per block. Here are heatmaps of the attention weights for two separate heads. You can see the values in the plots are slightly different, showing the different weight initializations. During training they will be taught to attend to different representations of the inputs.
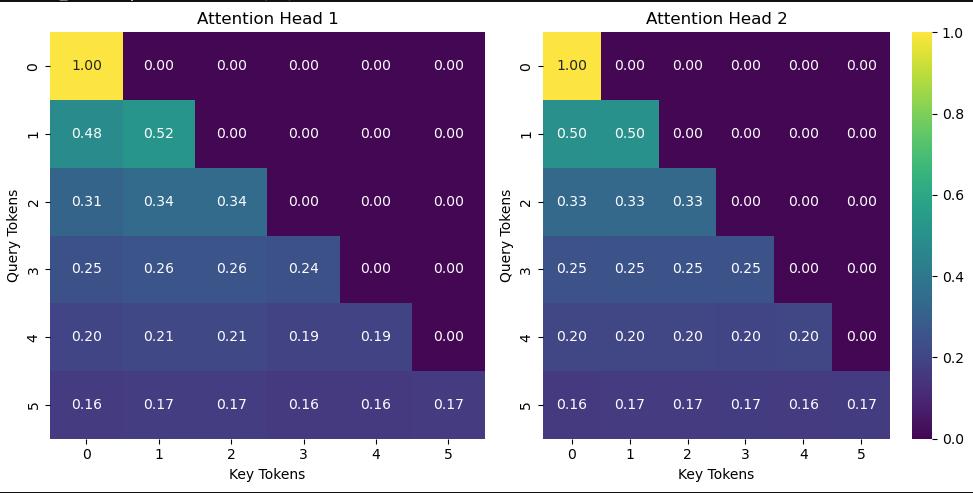
Attention weight heatmaps for two separate heads.
Conclusion
I followed the attention chapter of Sebastian Raschka's book "Build a Large Language Model (From Scratch)", which I already read and built. This time, I could focus on the math, implementation, and key details of attention. I challenged myself to implement the self-attention, causal attention, and multi-head attention classes from scratch which helped solidify my understanding of attention, a key part of transformer based LLMs.
References
- Build a Large Language Model (From Scratch)" by Sebastian Raschka
- https://www.youtube.com/watch?v=eMlx5fFNoYc
- https://arxiv.org/pdf/1706.03762